前言
本文是以笔者学习中遇到的一个小场景作为线索,从而引发笔者诸如“什么是进程?”“什么是线程?” “GCD 和线程关系是什么?” “NSRunLoop 是什么?”“NSRunLoop 和线程关系是什么?”等诸多疑问,随后又根据这些疑问,一步步抽丝剥茧,找寻这些问题答案的文章。
本文篇幅较长,文章梗概如下。
- 一个在 OS X Command Line 中出现的与线程有关的场景。
- 探究进程和线程
- 探究 GCD 库
- 探究 BSD/POSIX 的 pthread 和 Mach 抽象层的 thread
- 探究 NSRunloop(CFRunloop)
如果你对线程底层实现以及 XNU 内核感兴趣,或许这篇文章会对你有帮助。本文大部分是探究的过程,如果想跳过过程,可直接点击结论
场景再现
某天,笔者想在 OS X Command Line 的 main 函数直接创建 timer,输出 CPU 使用和内存使用数据。代码如下所示。
dispatch_queue_t monitor_queue() { |
然而,运行程序之后,结果并未如笔者所期望的那样,触发 timer 设置的回调 block,而是直接终止进程,这是什么情况?—— 为什么在 iOS 工程下,可以得到想要的数据输出。然而,完全相同的代码直接复制到命令行工程中,main 函数却直接 return 而结束进程。
笔者百思不解,最终只能求助同事,同事建议尝试开启当前线程的 Run Loop 试试。果然,控制台可以正常输出每秒的 CPU 和内存的使用数据了。然而,笔者就奇怪了,为什么要手动开启线程的 Run Loop 呢?不是说好的主线程的 Run Loop 不需要手动开启嘛,为什么到命令行这就要手动开启呢?这是因为网上大多数文章没有指明 NSRunLoop 默认是在 macOS/iOS 应用的工程中开启,从而也误导了笔者认为 Command Line 同样会开启主线程的运行循环。
在上述这个例子中,开启 Run Loop 以避免线程结束的这种方式,就是所谓的“创建常驻线程(线程保活)”,而此场景中的线程只不过是主线程而已。 在 macOS/iOS 应用中的 AppDelegate(继承自 NSApplicationDelegate/UIApplicationDelegate),已经封装好 Run Loop 对象的相关操作。所以,就不需要开发者手动开启,而作为 Command Line 只包含简单的 main 函数,因而自然不会进行 Run Loop 的开启操作。 所以,当程序顺序执行完成,主线程的 main 函数就直接 return 从而结束当前进程,而并不等待回调函数中的异步操作了。
虽然 GCD timer 回调事件没有正常触发的问题已经解决了,但笔者仍不免产生这样的疑问,到底什么是进程?什么是线程?GCD 和线程关系是什么?RunLoop 和线程关系是什么?所以,就从这些疑问开始,慢慢找寻其答案。
进程和线程
进程
《OS X and iOS Kernel Programming》一书中对进程是这样描述的:
When the user launches an application, the operating system loads the program’s code and data into memory from disk and begins executing its code. A program being executed is known as a “process.” Unlike a program, a process is an active entity, and consists of a snapshot of the state of the program at a single instance during execution.
大意为,当用户启动一个应用,系统将程序的源码和数据从磁盘加载到内存中,并且开始执行他的源码。一个进程即一个正被执行中的程序。与程序不同,一个进程是一个活跃的实体,并且包含了程序作为单个实例在执行期间状态的快照。
所以,从上述描述我们就可以得知,我们所谓的进程,就是在内存中执行着的程序文件。比如,一个 ls 命令,其实就是一个可执行的文件,当其在执行时就是一个进程。而我们如果需要查看当前所执行中的进程,可以使用 ps awx 命令。
与此同时,也可以更加了解“UNIX 操作系统一切皆文件”基本哲学的奥义。
思维扩展 **内核也是一个进程,或者说内核也是内存中执行着的程序文件。**如果想直接拿到内核文件,可以在内存中计算好内存偏移量,然后直接 dump 出来。笔者暂未找到直接 dump 内核的方法,只是某次面试时,面试官老师提过这么一个案例,故而记着了。 虽未找到 dump 内核的具体方式,但查到有个导出内核符号表的案例,参见 http://bbs.iosre.com/t/kernel-symbols-where-are-you/595
线程
了解过进程的基本概念,再来看线程。在《Mac OS X and iOS Internals To the Apple’s Core》中是这样定义线程的:
Modern operating systems no longer treat processes as the basic units of operation, instead work with threads. A thread is merely a distinct register state, and more than one can exist in a given process. All threads share the virtual memory space, descriptors and handles.
现在操作系统一部将进程视为操作的基本单元,取而代之的是线程。一个线程只不过是一组寄存器的状态,并且一个进程存在多个线程。所有的线程共享虚拟内存空间,文件描述和句柄。
思维扩展 关于“一个线程只不过是一组寄存器的状态”笔者也进行了其他相关资料的考证。可参见如下资料。
资源竞争
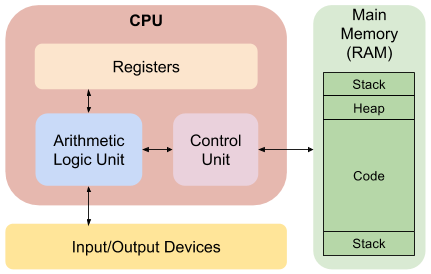
从进程和线程的基本概念可知,进程是内存(RAM)中执行中的程序文件,而线程则是 CPU 一组寄存器的状态。也就是说,所谓进程和线程对象,其实是操作系统在底层硬件的物理元件之上抽象出的实体对象,方便用户(开发人员)编写程序来对系统资源进行合理使用。
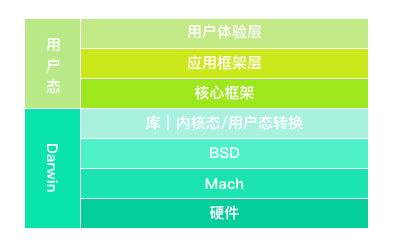
上图所示为 macOS(OS X)/iOS 的架构图。其中,上层是 macOS/iOS 的用户态架构,下层是 macOS/iOS 的 Darwin(内核态)架构。而 Darwin 最底层是硬件,依次往上分别是 Mach 抽象层、BSD 层,以及内核态/用户态转换层。
我们知道,在计算机中内存和 CPU 的资源都是有限的,所以,内存和 CPU 的资源竞争都非常激烈,接下来就看一下操作系统是如何解决内存和 CPU 资源竞争问题的。
解决内存资源的竞争:分页
为了解决内存的竞争,操作系统提供了虚拟内存(Virtual Memory)这样的解决方案,操作系统通常使用一种称为分页(Paging)的方案,实现虚拟地址(硬盘 disk)到物理地址(内存 RAM)的转换。_
—— 摘自《OS X and iOS Kernel Programming》一书
OS X 和 iOS 都采用了分页机制,但是对于 iOS 而言,分页并没有进行 RAM 和磁盘的交换(Swap),所以,iOS 的内存管理也就仅限于 RAM 的管理。由于本文主要探究线程是什么,所以,对于分页的探究就浅尝辄止了。
解决 CPU 资源的竞争:调度
内存的资源竞争,操作系统是通过虚拟内存分页解决的。CPU 的资源竞争则是通过调度(Schedule)解决的。
对于操作系统来说,线程是调度的基本单位;当操作系统调度程序考虑接下来在CPU上调度什么时,只需查看系统上的活动线程。进程如若执行,至少要包含一个线程;一个新进程开始运行时,操作系统会自动为其创建初始线程。 调度器有两个作用:防止CPU闲置,否则会浪费宝贵的硬件资源;让所有线程公平地访问CPU,防止因单个线程独占CPU而导致其他线程无法运行。为此,一个线程会在可用的CPU内核上调度执行,直至以下任一事件发生。
—— 《OS X and iOS Kernel Programming》
GCD 源码研读
上文已经了解了线程的基本概念,对于 OS X/iOS 的多线程并发编程,GCD 为开发者提供了简单的方式来利用多核处理器的特性,从而提高应用程序并发计算的的效率。
GCD 的作用是,并发执行在多核硬件上提交工作的源码,从而派遣被系统管理的队列。接下来,不妨以开篇场景还原中的代码为线索,按图索骥,看一下 GCD 源码是如何设计的。
创建 GCD 队列
dispatch_queue_t dispatch_queue_create(const char *label, dispatch_queue_attr_t attr) { |
上段代码主要是对 GCD 队列进行创建和初始化操作,其中 _dispatch_queue_init 初始化 GCD 队列实例并。再详细看 _dispatch_queue_init 这个函数的函数体。
_dispatch_queue_init(dispatch_queue_t dq) { |
_dispatch_queue_init 函数体调用了 _dispatch_get_root_queue,并且参数 priority 值为 0(DISPATCH_QUEUE_PRIORITY_DEFAULT),overcommit 为 true,则返回 &_dispatch_root_queues[3]
而 _dispatch_root_queues 是一个队列数组,可以得知,&_dispatch_root_queues[3] 即为 “com.apple.root.default-priority“ 这个队列,而我们刚才确实也是利用 GCD 创建的后台线程的队列。稍后,我们将探究 GCD 队列与 pthread 的关系。
以上这段代码利用的是 libdispatch-84.5 的源码,新版本的 _dispatch_root_queues 会有不同,后面探究过程中会使用新版本的定义。
设置 Timer 事件回调
在本例中 dispatch_source_create 创建 Timer 的 source,而 dispatch_source_set_timer 进行 timer 的初始化,具体代码不做深究,仔细来看 dispatch_source_set_event_handler 这个方法的源码。
void dispatch_source_set_event_handler(dispatch_source_t ds, dispatch_block_t handler) { |
调用 dispatch_barrier_async_f,设置栅栏函数,使得并发队列仅执行 _dispatch_source_set_event_handler2 这个函数,并且将 handler 作为 context 上下文参数传给 _dispatch_source_set_event_handler2。
在 _dispatch_source_set_event_handler2 这个函数中 _dispatch_queue_get_current 比较有意思,是获得当前队列,来看看这个函数的具体实现。
static inline dispatch_queue_t _dispatch_queue_get_current(void) { |
上述代码是获得当前的队列的具体实现 _dispatch_queue_get_current 调用了 _dispatch_thread_getspecific 函数,在 _dispatch_thread_getspecific 函数中,当 _pthread 不存在直接的 tsd 数据时调用了函数 pthread_getspecific,然而该函数并未在 GCD 的库中,而是在 Libc 库的 pthreads(或是 libpthread) 中。
pthread_self() 获得线程后,将 self->tsd[key-1] 赋值给 res 并返回,而 tsd 是一个指针数组,是线程的特定数据。当 pthread_getspecific 函数 return 后 _dispatch_thread_getspecific 将返回 dispatch_queue_t 类型的变量。至此,我们至少可以确定 GCD 队列和 pthread 有一定关系,然而到底具体是怎样的关系,我们可以通过查看线程的调用栈,来继续探索两者之间的关系。如下图,在 event handler 的回调被唤起时,设置断点,查看当前线程的调用栈。
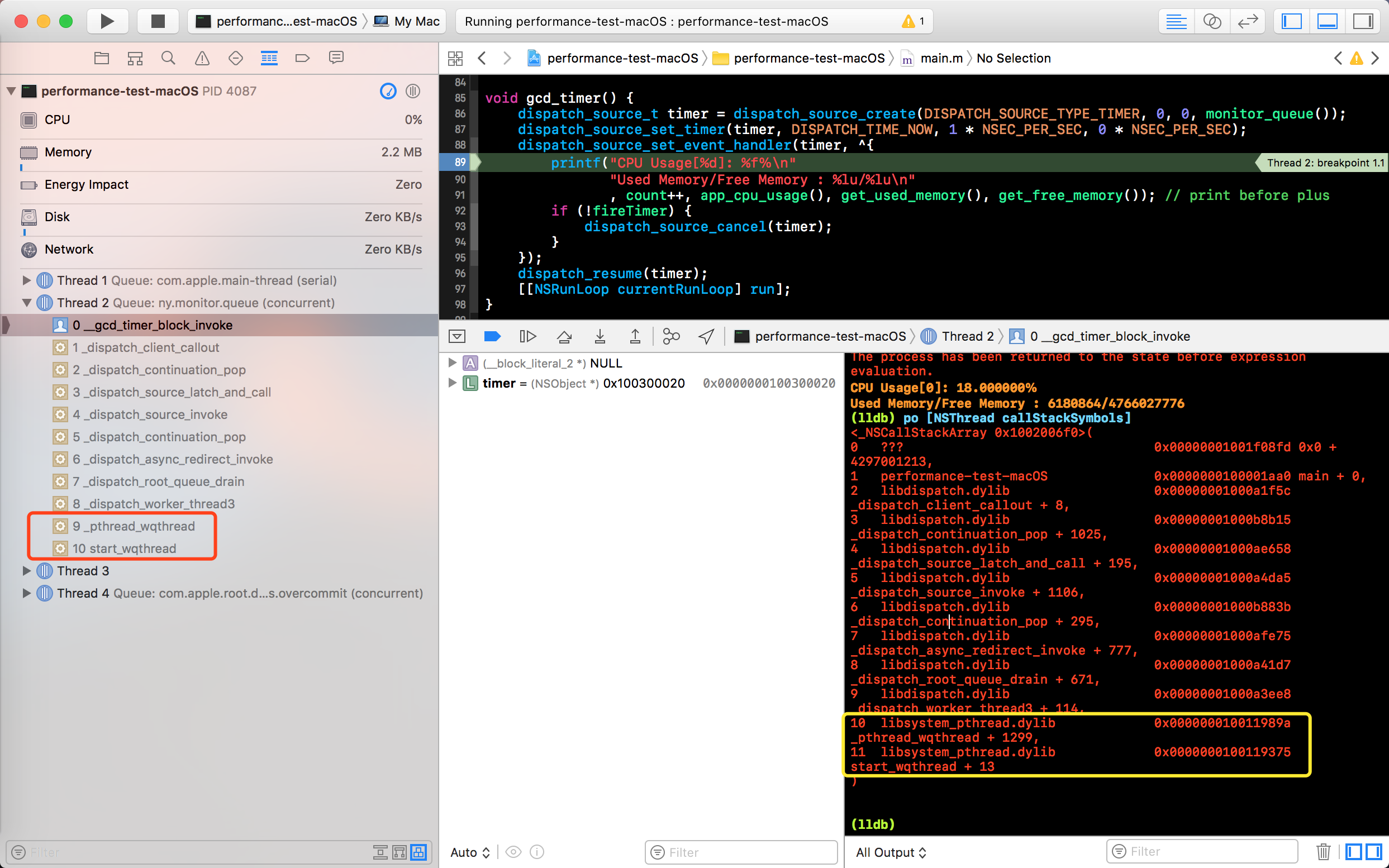
在 GCD timer 回调的调用栈中,我们可以看到,虽然我们的队列名称一直是 “ny.monitor.queue” ,但是执行回调的线程却不一定相同。这是因为,并发队列是多个线程执行任务,而串行队列只有一个线程执行。比较特殊的就是主队列,只在主线程上执行任务。
除此之外,观察调用栈的函数调用顺序,先是调用 _start_wqthread 这个方法,之后调用 __pthread_wqthread 方法,然后,调用 _dispatch_worker_thread3 这个函数。那么接下来就具体看这几个函数实现。
_start_wqthread 是汇编指令编写的代码,只有内核才会跳进这里的代码区域,然后调用 __pthread_wqthread 函数。 __pthread_wqthread 函数是内核队列的入口函数,继续看调用栈调用的函数。
static void _dispatch_worker_thread3(pthread_priority_t pp) { |
在上述代码中,_dispatch_worker_thread3 调用并返回 _dispatch_worker_thread4,_dispatch_worker_thread4 调用了 _dispatch_queue_concurrent_drain_one,最终调用了 _dispatch_queue_wakeup_global。
_dispatch_queue_wakeup_global 的函数体中,*struct dispatch_root_queue_context_s qc = dq->do_ctxt; 这句代码是将 dispatch queue 的 dispatch object 指向的 context 赋值给了 dispatch_root_queue_context_s 指针。
首先来看 dispatch_queue_t 是如何定义的。
|
DISPATCH_DECL(name) 函数就是将 name##_s 的名字的结构体 重定义为 name##_t 的指针类型。而 DISPATCH_STRUCT_HEADER(x, y) 函数是在预处理*阶段,将 dispatch_queue_s 结构体的宏定义的函数,替换成已经定义好的成员变量。所以,dispatch_queue_s 结构体就有了 do_ctxt 这个成员变量。
接下来看 dispatch_root_queue_context_s 结构体的定义。
|
从 dispatch_root_queue_context_s 结构体的定义中可以观察到,有一个成员变量 dgq_kworkqueue 是 pthread_workqueue_t 类型的。而 pthread_workqueue_t 类型是 BSD 层的工作队列类型。
也就是说,GCD 队列 dispatch_queue_t 的 dispatch_root_queue_context_s 类型的上下文成员变量 do_ctxt,其实就是 BSD 层的 pthread_workqueue_t 一层包装。
而在 _dispatch_queue_wakeup_global 的函数中,当 GCD 队列的上下文 do_ctxt 存在,并且 dgq_pending 的值改为 1 时,调用 pthread_workqueue_additem_np 函数,该函数会通知 XNU 层的 workqueue 增加相应执行的项目,根据该通知 XNU 内核基于系统状态判断是否要生成线程。
对于 GCD 队列,libdispatch-685 版的 GCD 队列类型如下。
enum { |
与上述枚举类型相对应的 GCD 队列 label 名称为:
- com.apple.root.maintenance-qos
- com.apple.root.maintenance-qos.overcommit
- com.apple.root.background-qos
- com.apple.root.background-qos.overcommit
- com.apple.root.utility-qos
- com.apple.root.utility-qos.overcommit
- com.apple.root.default-qos
- com.apple.root.default-qos.overcommit
- com.apple.root.user-initiated-qos
- com.apple.root.user-initiated-qos.overcommit
- com.apple.root.user-interactive-qos
- com.apple.root.user-interactive-qos.overcommit
从以上队列名称中,发现一个新词 qos,何为 QoS?苹果官方文档解释如下:
A quality of service (QoS) class categorizes work to be performed on a DispatchQueue. By specifying a QoS to work, you indicate its importance, and the system prioritizes it and schedules it accordingly.
QoS 类将工作事务在 GCD 队列上分类执行。通过具体说明将要工作的 QoS,开发者指明 QoS 的重要性,从而,系统令它具有更高优先级,并且相应地调度他。
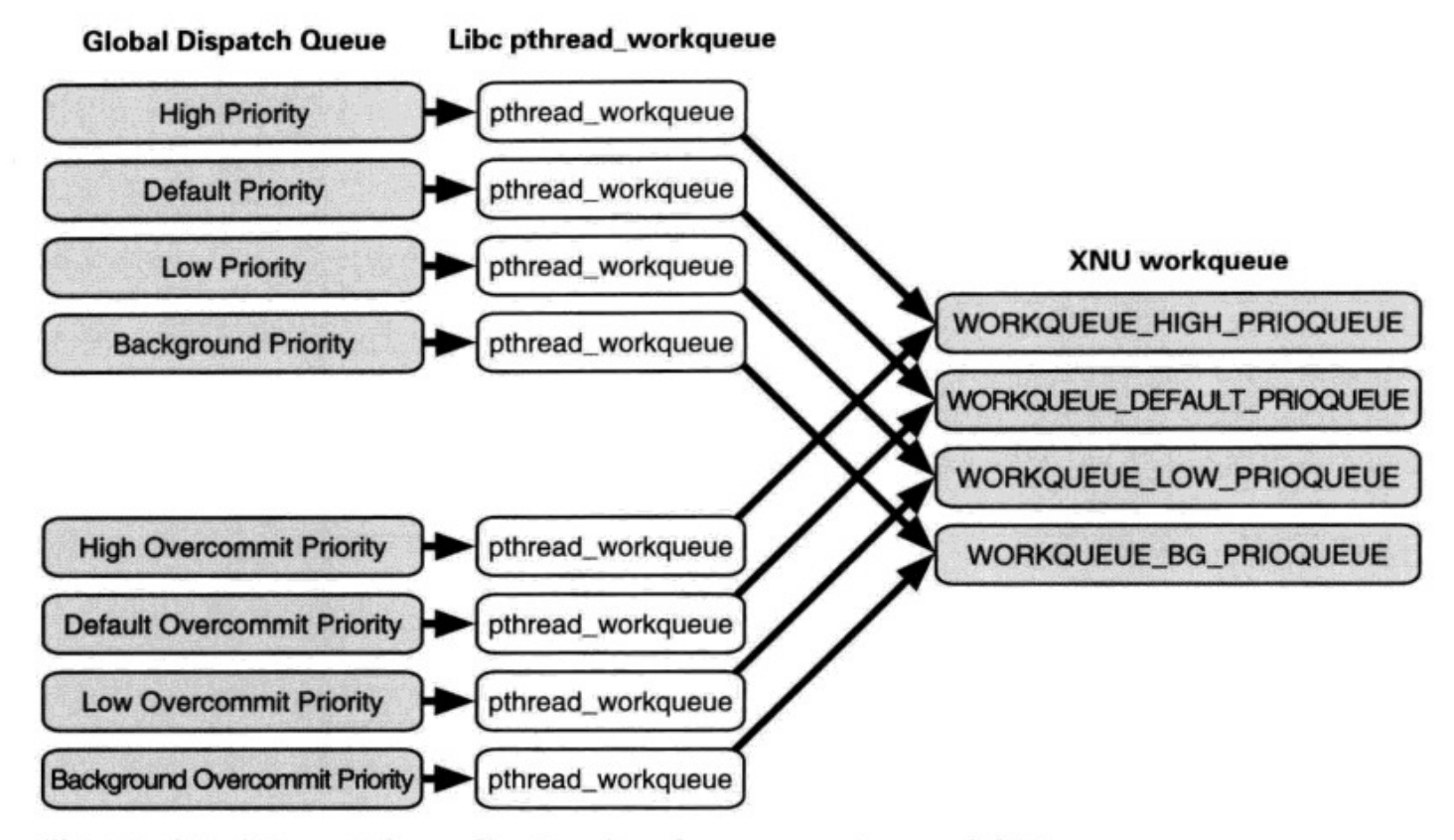
上图很清晰地展示了 dispatch_queue_t 和 pthread_workqueue_t 的对应关系,则可知 GCD 队列除了对优先级 Priority 对队列进行区分,还会根据 Overcommit 的不同区分不同队列类型。
Overcommit 级别就是 QoS 机制为用户提供指明队列优先级的类型。XNU 内核基于系统状态判断是否要生成线程,而对于 Overcommit 队列,不论操作系统多么繁忙,内核都会为之创建一个新的线程。

上图展示了用户自定义队列、GCD 队列以及线程之间的对应关系。
GCD 暴露了五个不同的队列:运行在主线程的主队列,三个不同优先级的后台队列,以及一个拥有更低优先级被 I/O 限制的后台队列。除此之外,开发者可以创建串行或并发的自定义队列。自定义队列是一个强大的抽象的同时,开发人员在这些队列上调度的所有 block,最终缓缓流至系统的全局队列,以及他们的线程池。
我们已经了解到,GCD 队列和线程队列的关系,并且当 GCD 队列是 Overcommit 类型时,不论操作系统多么繁忙,内核都会为之创建一个新的线程。GCD 队列 dispatch_root_queue_context_s 的上下文变量中,有一个用来记录线程池大小的字段 dgq_thread_pool_size。而对于执行的任务来说,所执行的线程具体是哪个线程,则是通过 GCD 的线程池(Thread Pool)来进行调度。
工作队列是 OS X/iOS 为应用程序提供多线程支持的一种机制,GCD 正是是基于这种机制进行设计的。此外,NSOperationQueue 是 GCD 队列模型的一种 Cocoa 抽象。与 GCD 提供低级别(编程语言层次)的控制不同,操作队列在此之上实现了一些便捷的特性,对应用开发者而言,是最佳且最安全的选择。
思维扩展 我们通过研读 GCD 源码可以知道,GCD 是 Apple 公司用 C 语言编写的工作队列管理的开源库,调用了 pthread 相关方法,使得开发人员进行 CPU 线程调度、队列管理更加方便。那么,既然 GCD 是用 C 语言编写的,那能否在其他 OS 上进行移植呢?
答案是否定的。因为 GCD 是基于 mach 调用来编写的,而 mach 调用仅适用于 OS X/iOS 的 Darwin 内核,所以,虽然 GCD 非常好用,但却不能移植到 Linux/Windows 操作系统上。然而,遵从 POSIX 规范的 pthread 却可以跨平台开发。接下来就详细看一下 pthread 的相关内容。十分感谢多弗朗明哥大神看完之后指出我的错误,大神原话:“GCD 是可以移植到其他平台,我用过 Windows 版本的,性能肯定没有 Darwin 内核的好(毕竟底层有优化支持 ),而且不支持 block,传的是函数指针。补充一下微软的 WinObjc 项目也内置了 GCD,还有支不支持 block 取决于编译器。”
再次感谢多弗朗明哥大神的校正,又学到新技能了,有时间再接触一下 Windows 版本的 GCD,这样一套 API 多平台都可以使用,那真真是极好的 :) 学习成本就低了。十分感谢大神赐教~ 😝
Thead
我们通过阅读 GCD 源码,已经搞清楚 GCD 队列和 pthread 队列的对应关系,也了解了 GCD 的队列和线程之间的关系。那么下面我们就来探究线程的具体实现原理。
BSD 层的 pthread
OS X/iOS 的基本架构上文已经提到,OS X/iOS 的核心是 Darwin,而 Darwin 的架构从上往下依次是用户态/内核态的转换、BSD 层、Mach 抽象层,最底层是硬件相关接口。而 BSD 层建立在 Mach 抽象层之上,并提供了 POSIX 接口,以及一些 BSD 的系统调用。
首先,我们来了解什么是 POSIX。Wikipedia 的解释如下。
The Portable Operating System Interface (POSIX) is a family of standards specified by the IEEE Computer Society for maintaining compatibility between operating systems. POSIX defines the application programming interface (API), along with command line shells and utility interfaces, for software compatibility with variants of Unix and other operating systems.
可移植操作系统接口(POSIX)是由 IEEE 计算机学会指定的用于维护操作系统之间兼容性的一系列标准。 POSIX 定义了应用程序编程接口(API)以及命令行shell和实用程序接口,用于与 Unix 和其他操作系统的变体进行软件兼容。
以 pthread 为例, pthread 的相关方法,不光可以在 Linux 操作系统上调用,还可以在 OS X 和 Windows 操作系统上调用。比如创建线程,都是调用 pthread_create 函数,这对于 Linux/OS X/Windows 其实是一致的。
然而,对于不同 OS 而言,pthread 的具体封装并不相同,就 OS X 而言,BSD 层暴露的 POSIX 接口,其实都是 Mach 抽象层的再次封装。下面就具体探讨 pthread 和 Mach 抽象层的 thread 的关系。 pthread 类型是在 Libc 库的 pthread_internals.h 文件中定义的。如下代码是采用 Libc-498.1.7 的源码。
typedef struct _pthread |
上述代码,就是 pthread 在 Libc-498.1.7 的 pthread_internals.h 文件中的定义。在定义中,我们可以看到 mach_port_t 类型的成员变量。mach_port_t 类型实际上就是 unsigned int 重定义类型,是一个已经命名的端口权限。比如,kernel_thread 就是内核线程与 BSD 层的线程绑定的端口。
在 Mach 中,进程、线程和虚拟内存都是对象,所有的对象都有自己的属性。Mach 通过消息 mach_msg() 传递的方式实现对象和对象之间的通信,消息在端口 mach_port_t 之间传递。所有的 Mach 原生对象都是通过对应的端口访问的。
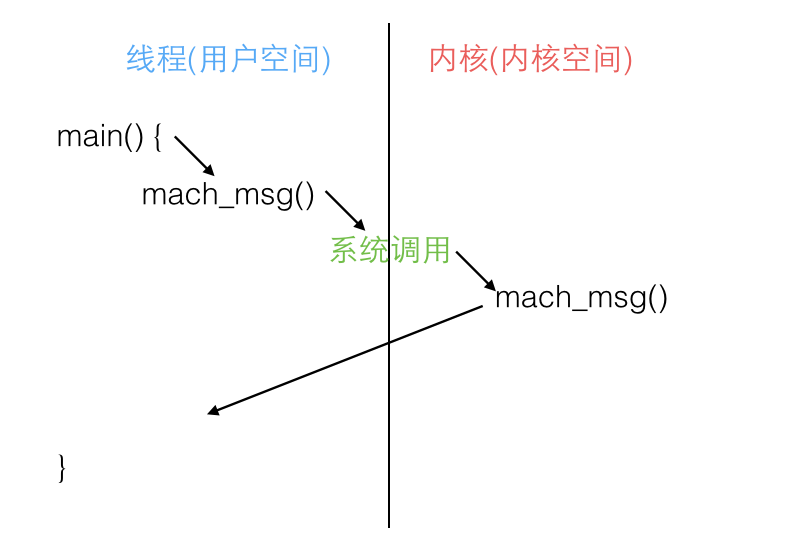
比如,下面的代码提供了获得当前主机可用的内存大小的方法。若想要获取内存当前可使用量,就必须先得到当前主机对象 host 的端口 mach_host_self(),之后再向对象发送消息。
unsigned long get_free_memory() { |
Mach thread 与 pthread 的关系
上一节我们已经对 pthread 有所了解,对于 pthread 是如何在 Mach 层上对线程进行封装的就暂不细究,下面简单来看一下,对于 XNU 而言,线程是如何创建的,从而也可以看出 pthread 和 Mach 抽象层 thread 是怎样的关系。
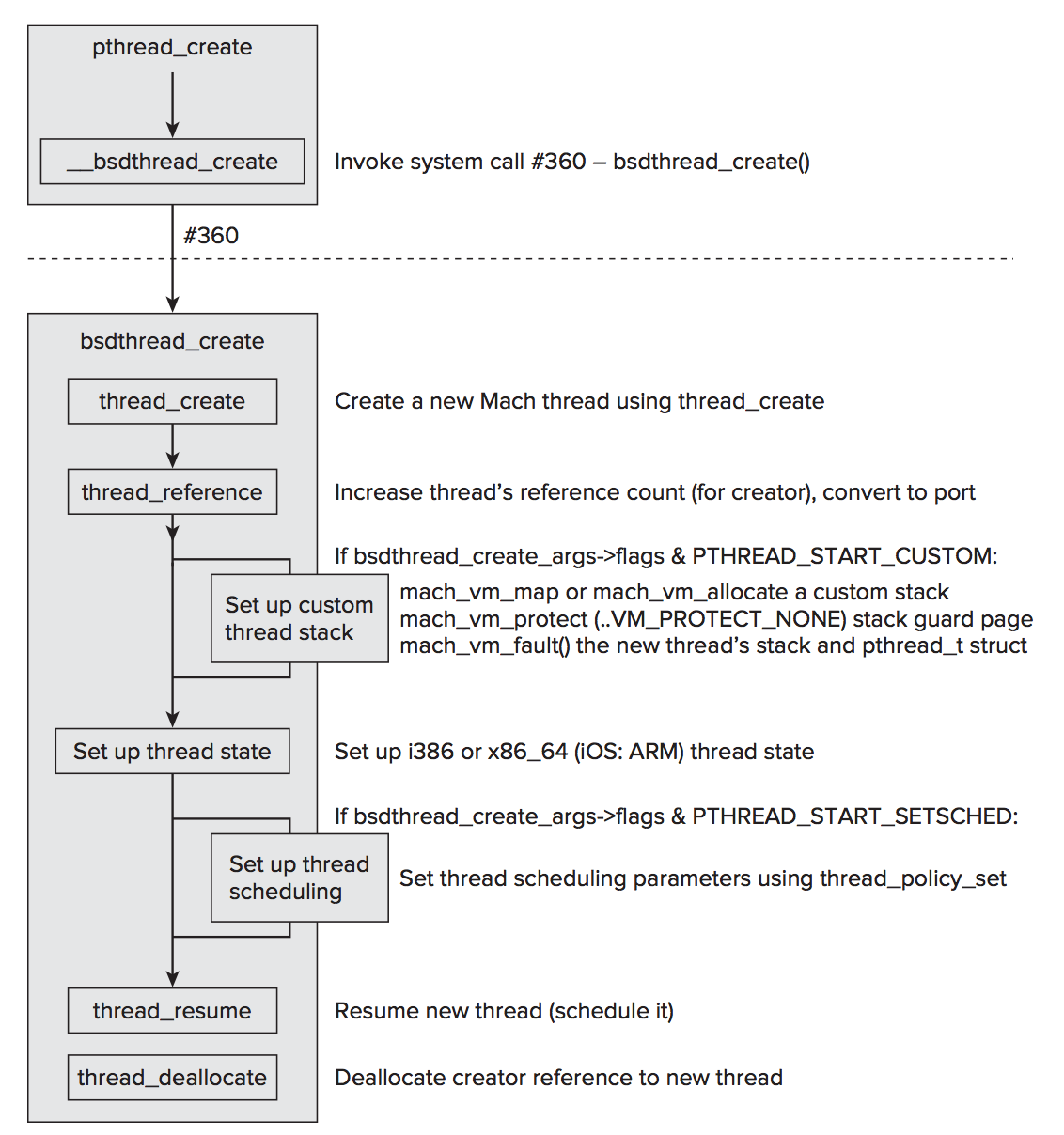
用户态的调用开始于 pthread_create 的调用。这个函数做的工作并不多,因为主要工作是由 bsdthread_create 系统调用完成的,这个系统调用的实现是在 bsd/kern/pthread_synch.c 文件中。bsdthread_create() 只不过是对 Mach 线程创建的复杂包装。真正的线程创建是由底层 Mach 层完成的。**bsdthread_create()**负责的工作是设置线程栈(如果指定了自定义栈),设置机器相关的线程状态,以及设置自定义调度参数等。
Run Loop
开篇场景的疑问已经解决了:三个进程和线程的基本概念、GCD 队列和线程的关系,以及线程在 BSD 层和 Mach 抽象的的定义和关系,下面就来继续探究 Run Loop 相关技术原理。
对于本文中的场景,假设我们不用 Run Loop 去开启循环,而是直接用 While 循环调用 CPU 和 Memory 的函数,虽然依旧可以保证主线程不结束,但会导致 CPU 使用率飙升,因而,Apple 提供了 CFRunLoop 来优化应用程序的运行循环。
那么,同样是循环,那这个循环的具体代码在哪里?Run Loop与线程有怎样的关系?带着疑问开始探究。
NSRunLoop 与 CFRunLoop
为了让 Command Line 的主线程能够常驻,在开篇代码的 dispatch_resume(timer) 后面调用了 [[NSRunLoop currentRunLoop] run],从而开启运行循环。 NSRunLoop 并不是开源的,Apple 暴露了头文件,可以简单看一下 NSRunLoop 相关属性和方法。
NS_ASSUME_NONNULL_BEGIN |
在 NSRunLoop 的方法中,提供了一个获取当前 CFRunLoop 的方法 getCFRunLoop,点击 Pause program execution 按钮,暂停主线程执行的任务,添加 [NSRunLoop currentRunLoop] 观察对象。
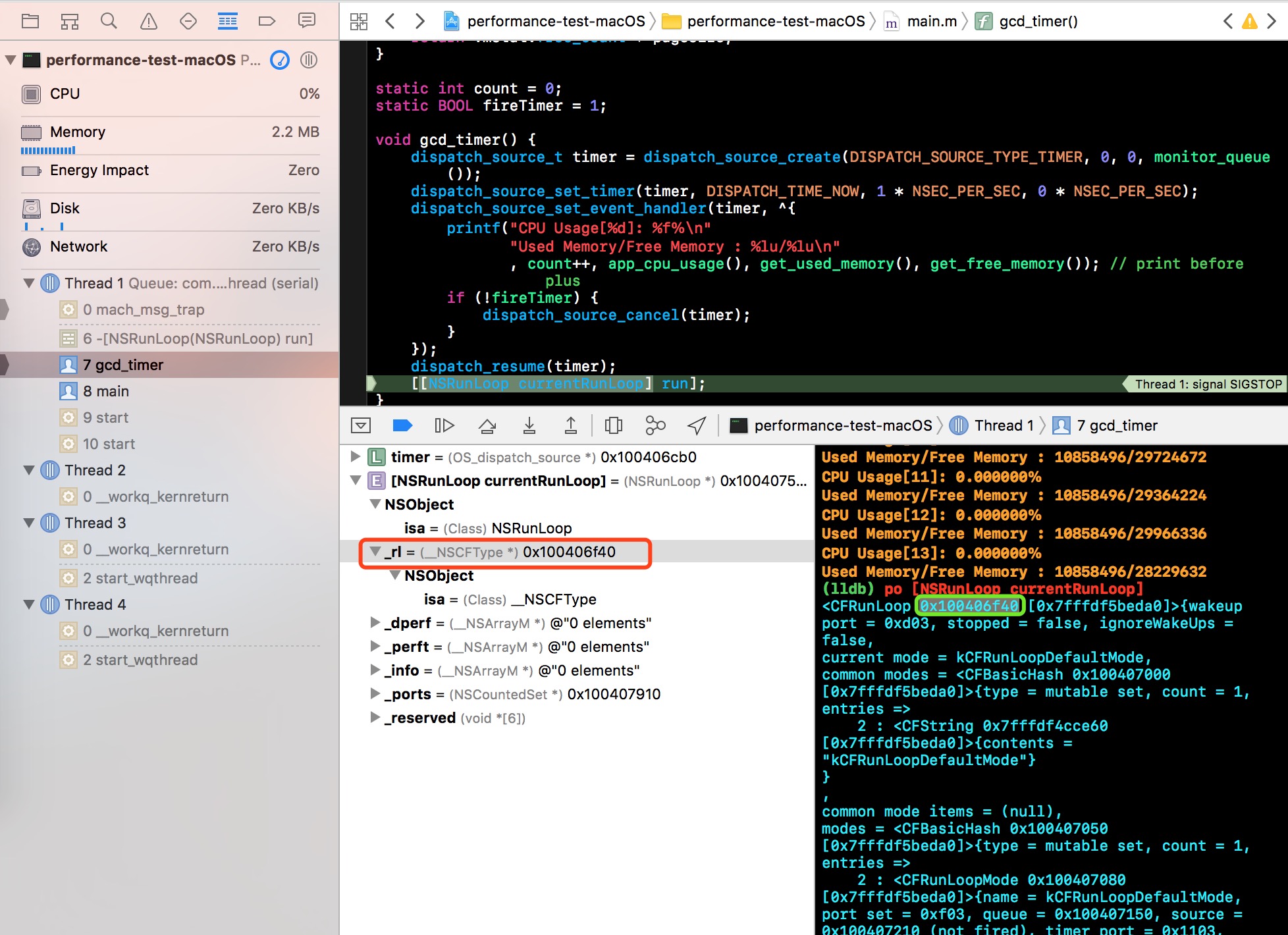
[NSRunLoop currentRunLoop] 的私有属性 _rl 的内存地址,与控制台输出的 CFRunLoop 的内存地址相同,都是 0x100406f40。所以,我们可以确定私有属性 _rl 就是 [NSRunLoop currentRunLoop] 所引用的 CFRunLoop 对象。从而可知 NSRunLoop 是基于 CFRunLoop 的封装。
NSRunLoop 类并不是线程安全的,如果开发者使用 NSRunLoop 类修改 Run Loop ,那么只能从拥有 Run Loop 的同一线程执行此操作。将输入源或计时器添加到属于不同线程的运行循环,可能会导致代码以意想不到的方式崩溃或表现。
CFRunLoop 相关 API
struct __CFRunLoop { |
上述代码是 CF-1153.18 CFRunLoop.c 文件中 __CFRunLoop 的定义。由 __CFRunLoop 的定义中可以观察到存在 pthread_t 类型的 _pthread 成员变量,表明线程和 RunLoop 之间是一一对应的关系,RunLoop 引用了 _pthread 指针,所以在使用 RunLoop 时需要注意释放线程对象,避免引起内存的循环引用。
另外, __CFRunLoop 的结构体存在 CFRunLoopModeRef 类型的 _currentMode 成员变量,而 CFRunLoopModeRef 的引用类型是 __CFRunLoopMode 的指针变量。
typedef struct __CFRunLoopMode *CFRunLoopModeRef; |
从 __CFRunLoopMode 结构体定义中,可以观察到有这样几个比较重要的字段,CFMutableSetRef 集合类型的 _sources0 和 _sources1,CFMutableArrayRef 数组类型的 _observers 和 _timers。
由此,我们可以得出如下的对应关系图。
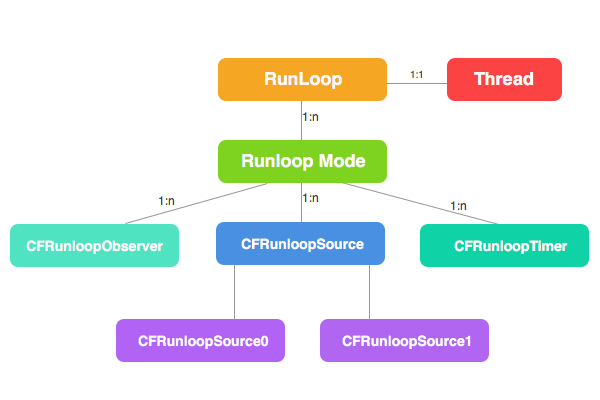
如上图所示, RunLoop 和 Thread 是一一对应的关系,RunLoop 和 RunLoop Mode 是一对多的关系。RunLoop Mode 分别和 RunLoop Observer 、RunLoop Timer、RunLoop Source 是一对多的关系。并且 RunLoop Source 分为 Source0 和 Source1 两种类型。
在 CFRunLoop.h 文件中对外开放了 CFRunLoopRef、CFRunLoopSourceRef、CFRunLoopObserverRef、CFRunLoopTimerRef 这几个类型。
typedef struct __CFRunLoop * CFRunLoopRef; |
那接下来就分别来看一下如何使用这些类型。
Observer
观察者 CFRunLoopObserverRef 在运行循环本身的执行期间,会在特殊活动状态时触发,比如,休眠、唤醒等状态。所以,观察者常应用于 App 的实时卡顿监控。这里就简单介绍一个创建观察者的例子,来了解 CFRunLoopObserverRef 相关 API 的使用。
- (void)threadMain { |
创建一个 RunLoopManager 类,并实现 threadMain 方法,在 *threadMain 方法实现中,创建观察者,并实现观察者的回调函数 MyRunLoopObserver。
void MyRunLoopObserver(CFRunLoopObserverRef observer, CFRunLoopActivity activity, void* info) { |
之后向当前的 RunLoop 中添加 CFRunLoopObserverRef 的观察者。然后创建 NSTimer 并每秒处发一次 show 方法。创建一个 do-while 循环,使得每隔 5 秒就重新启动 RunLoop 直到 loopCount 变为 0 时停止。
代码编写好之后,编译运行。当 threadMain 在后台线程调用时,每秒都会出发 Timer 的方法,同时也会触发 CFRunLoopObserverRef 的回调函数,从而输出 RunLoop 的不同活跃状态。直到 loopCount 变为 0 时停止 RunLoop。当 RunLoop 停止时,NSTimer 的定时器也就停止了。
由上文 CFRunLoop.h 开放的类型声明中可以得知, NSTimer 和 CFRunLoopTimerRef 是 toll-free bridged 的关系,两者可以混用。NSTimer 不是实时机制(real-time mechanism),只有添加了 timer 的 RunLoop 已经启动,并且能够检查定时器时间是否已经成为过去时,timer 才会被触发。
此外,当这段代码运行在主线程时,就不是上面的结果。而是控制台会一直输出 Timer 方法和 CFRunLoopObserverRef 的回调函数中打印的内容,不会停止当前的运行循环,也不会终止 Timer。也就是说 CFRunLoopStop(runloop) 函数对于主线程不起作用,不过假如起作用的话,那程序就顺序执行完 return 了,App 就不能正常运行了。
所以,基于 RunLoop 的 Timer 并不可靠。比如,如果在 TableView 滚动时,RunLoop 的 Mode 就由 NSDefaultRunLoopMode 变为 UITrackingRunLoopMode,必须手动将 NSTimer 的定时器添加到 NSRunLoopCommonModes 模式中,才能保证 Timer 正常触发。
Timer
上文已经了解 NSTimer 是基于 RunLoop 的,并且可以和 CFRunLoopTimerRef 混用。所以,从另一个角度来说,RunLoop 也会引用应用程序中活跃状态的 Timer,很有可能造成内存的引用循环从而导致内存泄漏。但是作为学习而言,还是可以了解一下 CFRunLoopTimerRef 是如何创建的。
CFRunLoopRef runLoop = CFRunLoopGetCurrent(); |
思维扩展 CFRunLoopTimerRef 与 GCD Timer 的区别。 在上文中,我们已经了解到 GCD Timer 是利用 GCD Source 创建的,而 GCD Source 回调事件的执行,是内核态跳进 _start_wqthread 之后调用 __pthread_wqthread 方法最后唤起回调函数,并不依赖于 RunLoop。所以,当 RunLoop 的 Mode 改变或结束时,GCD Timer 也不会暂停或停止。而 NSTimer/CFRunLoopTimerRef 创建的 Timer 则会受 RunLoop 影响,从而丧失定时器的准确性。
Source
输入源与线程异步传递事件。事件的来源取决于输入源的类型,通常是两个类型,基于端口的输入源(Port-Based Sources)监视应用程序的 Mach 端口,自定义输入源(Custom Input Sources)监视自定义的事件源。
除了基于端口的源之外,Cocoa 还定义了一个自定义输入源,允许开发者在任何线程上执行选择器,比如,
- performSelectorOnMainThread:withObject:waitUntilDone:
- performSelector:onThread:withObject:waitUntilDone: 等。
自定义源的创建(Custom Input Sources)及使用,如下面源码所示。
CFRunLoopSourceRef runLoopSource; |
CFRunLoopRun
通过前文的探究,我们已经知道 RunLoop 是通过调用 CFRunLoopRun(void) 函数来开启当前线程的运行循环的。那么接下来就详细来看 CFRunLoopRun(void) 的实现。
void CFRunLoopRun(void) { /* DOES CALLOUT */ |
CFRunLoopRun(void) 函数体中,通过 do-while 判断 RunLoop 是否停止且是否结束来循环调用 CFRunLoopRunSpecific 函数, CFRunLoopRunSpecific 函数中先调用 __CFRunLoopDoObservers 通知 Observers,RunLoop 即将进入循环,然后调用 __CFRunLoopRun 进入内部循环。
static int32_t __CFRunLoopRun(CFRunLoopRef rl, CFRunLoopModeRef rlm, CFTimeInterval seconds, Boolean stopAfterHandle, CFRunLoopModeRef previousMode) { |
进入内部循环后,先通知观察者即将触发 Timer 回调,之后通知观察者即将触发 Source0 (非 Port-Based Sources)回调,执行被加入的回调 block。如果有 Source1 (Port-Based Sources) 处于 ready 状态,直接处理这个 Source1 然后跳转去处理消息。 通知观察者 RunLoop 的线程即将进入休眠(sleep)。调用 mach_msg 等待接受 mach_port 的消息。线程将进入休眠,直到被 Port-Based Sources 事件、定时器时间到,RunLoop 超时等事件唤醒。
RunLoop 的线程被唤醒后,通知观察者 RunLoop 的线程被唤醒了。如果一个 Timer 到时间了,那么触发这个 Timer 的回调。如果有 GCD 主队列的 block,执行 block。如果有 Source1 (Port-Based Sources) 发出事件,则处理该事件。如果 RunLoop 没超时,Mode 不为空,循环也没被停止,那继续循环。直到不满足条件,通知观察者 RunLoop 即将退出。
可以结合上文中 CFRunLoopObserverRef 创建 RunLoop 观察者的例子结合来理解 RunLoop 的不同状态的转换。
小结
本文是由一个实际场景为线索,展开了对进程、线程、 GCD 实现原理以及 Run Loop 实现原理等相关技术的探究。本文内容较多,对内容进行凝练概括,主要有以下几点。
- 一个进程是一个正被执行中的程序,与程序不同,一个进程是一个在内存中活跃的实体。
- 一个线程是一组寄存器的状态。
- 操作系统解决内存(RAM)资源竞争的方式是分页(Paging)。
- 操作系统解决 CPU 资源竞争的方式是调度(Scheduling)。
- 工作队列是 OS X/iOS 为应用程序提供多线程支持的一种机制,是 GCD 的基础机制。
- GCD 队列和 pthread 队列以及 BSD 层的工作队列存在对应关系。GCD 队列根据 Priority 和 Overcommit 的不同区分不同队列类型。而对于 Overcommit 队列,不论操作系统多么繁忙,内核都会为之创建一个新的线程。GCD 队列的线程由 **GCD 线程池(Thread Pool)**来调度。
- RunLoop 和 Thread 是一一对应的关系,RunLoop 和 RunLoop Mode 是一对多的关系。RunLoop Mode 分别和 RunLoop Observer 、RunLoop Timer、RunLoop Source 是一对多的关系。并且 RunLoop Source 分为 Source0 和 Source1 两种类型。
- 观察者 CFRunLoopObserverRef 在运行循环本身的执行期间,会在特殊活动状态时触发,比如,休眠、唤醒等状态,可以根据这一特性进行 iOS 实时卡顿监控。
- NSTimer 和 CFRunLoopTimerRef 是 toll-free bridged 的关系,两者可以混用,但由于 NSTimer 是基于 RunLoop 的,其所创建的定时器并不可靠。相对而言,GCD Timer 不依赖于 RunLoop,相对而言更加可靠,易用。
- 事件的来源取决于输入源的类型,通常是 Port-Based Sources 和 Custom Input Sources 两个类型。基于端口的输入源(Port-Based Sources)监视应用程序的 Mach 端口,自定义输入源(Custom Input Sources)监视自定义的事件源。
结论
综上所述,线程在物理上实际上是指一组 CPU 寄存器的状态,操作系统可以利用线程对程序要执行的任务进行调度。所以,Mach 抽象层(OS X 的内核 Darwin 的底层)就封装了 thread 这个类型,而在 BSD 层提供了 POSIX 的 pthread 接口,pthread 是 Mach thread 的一层封装。
Apple 公司提供了一种工作队列的机制用于任务调度,GCD 正是基于这种工作队列的机制研发的。GCD 提供了更方便的 API 用于调度任务,GCD 的主队列的任务在主线程上执行,其他 GCD 队列的线程则是由 GCD 的线程池管理的,这样开发者就不需要关心线程怎么分配任务,而只关心在哪个队列上执行怎样的任务,以及怎样执行任务(同步/异步)。
RunLoop 是保证不损耗 CPU 性能的前提下,利用事件循环(Event Loop)模式设计的一种让线程能随时处理事件但并不退出的循环。RunLoop 与线程实体(pthread)的关系是一一对应的,也会强引用线程对象(指针)。RunLoop 有多种 Mode,每种 Mode 对应多个 Source、Observer 和 Timer。
Source 是事件输入源(Input Sources),分为基于端口的源(Port-Based Sources)和自定义源(Custom Input Sources)。除了基于端口的源之外,Cocoa 还定义了一个自定义输入源,允许开发者在任何线程上执行选择器,比如,performSelectorOnMainThread:withObject:waitUntilDone:,performSelector:onThread:withObject:waitUntilDone: 等方法。
Observer 会在 RunLoop 的特定时刻被触发,可以根据这一特性进行 iOS 实时卡顿监控。
NSTimer 和 CFRunLoopTimerRef 是 toll-free bridged 的关系,两者可以混用,但由于 NSTimer 是基于 RunLoop 的,其所创建的定时器并不可靠。
小彩蛋
本文案例源码
十分感谢您能读到这,这篇文章比较偏低层原理。本文最初的 GCD 场景,是源于我想做一个系统资源的 Monitor 程序。而在解决场景问题,探究线程的过程中,我也学到了不少 mach 原语、mach 消息、mach 端口等相关技术。放上本文的案例源码,如果感兴趣可以看一下。 源码地址:https://github.com/niyaoyao/performance-monitor
Apple Opensource 查阅指南
Apple Opensource 的主页链接为 https://opensource.apple.com 。一开始笔者学习 Apple Opensource 无从下手,久了就发现个小规律,如下所示。
源码说明
由于单一版本具体函数的实现不全,因而,笔者结合不同版本的源码来进行原理的探究。
- 本文中所使用的 GCD 源码,采用 libdispatch-84.5 和 libdispatch-685 版本,大部分基于 libdispatch-84.5。
- XNU 内核代码采用 xnu-792、xnu-1456.1.26 和 xnu-3789.51.2。
- Libc 源码采用 Libc-498.1.7、Libc-1158.50.2。
- Core Foundation 源码采用 CF-299,CF-1152.14,CF-1153.18。
本文如有任何错误或问题欢迎到这里 提 issue,一起交流学习,共同进步成长 😊。
参考资料
- 《Mac OS X and iOS Internals: To the Apple’s Core》
- 《OS X and iOS Kernel Programming》
- 《High Performance iOS Apps》
- 《Objective-C 高级编程 —— iOS 与 OS X 多线程和内存管理》
- Concurrent Programming: APIs and Challenges https://www.objc.io/issues/2-concurrency/concurrency-apis-and-pitfalls/
- Threading Programming Guide——Run Loops https://developer.apple.com/library/content/documentation/Cocoa/Conceptual/Multithreading/RunLoopManagement/RunLoopManagement.html
- iOS线下分享《RunLoop》by 孙源@sunnyxx http://v.youku.com/v_show/id_XODgxODkzODI0.html?refer=pc-sns-1&spm=a2h0j.8191426.0.0
- 深入理解 RunLoop(ibireme) http://blog.ibireme.com/2015/05/18/runloop/
- 深入理解 RunLoop(独奏) http://honglu.me/2017/03/30/深入理解RunLoop/
- POSIX_Threads Wiki https://en.wikipedia.org/wiki/POSIX_Threads
- Thread_pool https://en.wikipedia.org/wiki/Thread_pool
- Quality of Service(QoS) https://developer.apple.com/reference/dispatch/dispatchqos

